Why  ?
?
The Julia open source programming language was launched back in 2012 and the first stable version was released in 2018 (for comparison Python launched in 1991 and Python 2 was released in 2000).
Julia was constructed to solve the two language problem. Still today the problem is widespread.
The two language problem
Before Julia appeared, programming languages could be divided into those which are blazingly fast but need significant extra time when coding (C, Fortran, C++, Rust), and languages with which you can quickly create something that works, but with slow performance (R, Python, Matlab).
Sometimes there is clear priority for fast runtime or fast development, but especially in data science you need both:
- You need speed because you are working with potentially large amounts of data.
- And you need an easy-to-use language because data science algorithms are usually mastered by mathematicians, statisticians, cognitive scientists, physicist, … and only rarely by full-fledged programmers.
Julia was designed from the ground up to solve this problem.
40x less energy consumption than Python
Pereira et. al.(2021) have ranked
programming languages by energy efficiency.
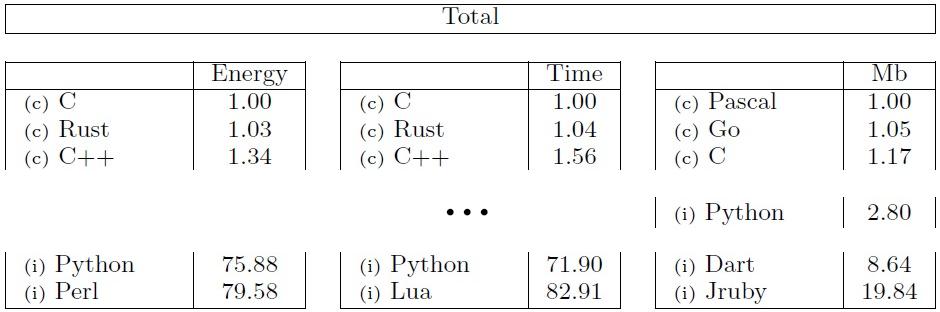
While in the original paper Julia was not included, it was added in an extra assessment for functional
languages.
The results are very impressive.
- Julia is second best functional language in energy efficiency (first being Rust)
- Among all tested languages, Julia needs slightly less energy compared to Java and about 40x less energy than Python.
A great performance, especially because Julia is just as dynamically typed as Python/R.
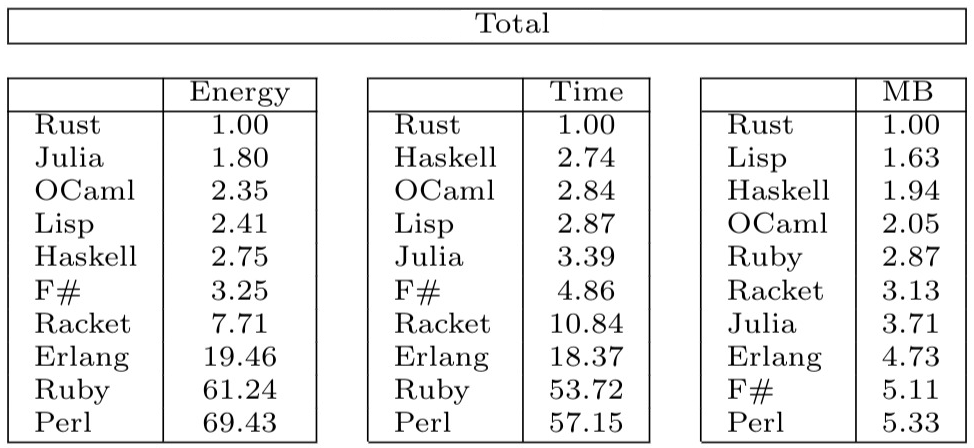
High Performance
Julia is fast. So fast, in fact, that if you find something slow, you are encouraged to report it as a Bug. Performance is the key commitment of this language.

Source: julia micro-benchmarks
The official micro benchmarks above show very well that Julia’s speed is comparable
to C and Rust. The pink dot is particularly interesting when comparing to Python.
It shows the matrix_statistics benchmark and even though the Python implementation
uses optimized C utilities like Numpy and OpenBLAS, it is an order of magnitude slower
than the Julia version. For more details, please follow the citation link.
Here’s an example user story from a team that has been tweaking Python for months only to see that Julia is still so much faster:
“In a few days of work, using Julia for the first time, I was able to produce a prototype that was 14 times faster than the heavily optimized Python code. There are a lot of reasons for that, but a few of the main ones were Julia’s light-weight threading model and the fact that profiling in Julia is tremendously easier, since it’s “Julia all the way down.” A few weeks later that code is in production, and has seen another ~2x speedup for a total of ~30x. As far as I can tell, the improvements I made wouldn’t be possible to replicate in Python right now. The fact that we spent 200+ expert hours on the Python version vs. 10 hours of a beginner’s time on the Julia also tells you a lot about the developer experience.
”Source: julia forum
Another comparison between Julia and Python shows even much higher speedups.
Developer friendly
A Julia solution is Julia “all the way down”. There is no barrier where developers have to switch to another language and bridge the two languages.
This massively simplifies development. Solutions are created faster, problems are more easily inspected, performance bottlenecks are found more reliably, and knowledge is better shared. Also new team members are much quicker onboarded.
“Julia’s advantage is that good performance is not limited to a small subset of “built-in” types and operations, and one can write high-level type-generic code that works on arbitrary user-defined types while remaining fast and memory-efficient. Types in languages like Python simply don’t provide enough information to the compiler
”Source: julia documentation
From a development perspective there are three key aspects of Julia:
- You can write generic functions which work for all types.
- You can specialize functions in case you know of a more effecient implementation for your concrete types.
- If you want to reuse functionality among different types, the only way to do that is to use generic functions.
This is an impressively simple design which is fully empowered by Julia’s perfected just-in-time (JIT) compilation. For the developer this means that you don’t have to worry about performance just until you really need it, and then they can specialize a tiny part of their system while the rest is reusable.
Well maintainable
Everything is composable.
- You want to add physical units to your numbers? Just import the package Unitful.jl and add them.
- You want error margins for your results? Just import Measurements.jl and add them.
- There are many more reusable components in the Julia ecosystem which would be impossible to share in other languages.
All your built functionality will still work the same, nothing needs to be rewritten.
It will also simplify your own project, and simplicity is the most important aspect in software development. Future adaptations can be added easily, without the fear that you need to do a massive rewrite. Maintenance is simplified, and your project will seamlessly outlive your crew change.
How does Julia do it?
Such composability is unprecedented and a unique feature of Julia’s programming paradigm. Julia is neither an object-oriented, nor a functional language. Instead it empowers a flexible function-overloading-mechanism, also called multiple dispatch.
An easy way to understand this distinction is to think of a cookbook. The different programming paradigms give different guidance on how to structure the recipes.
🥦 Broccoli
- Boiling
- Stew
🥕 Carrots
- Frying
- Boiling
easy to add a new ingredient by creating a new chapter
very difficult to add a new functionality — all chapters would have to be rewritten
Boiling
- 🥦 Broccoli
- 🥕 Carrots
Frying
- 🥕 Carrots
- 🧅 Onions
very difficult to add a new ingredient — all chapters would have to be rewritten
easy to add a new cooking method by creating a new chapter
- Stewing 🥦 Broccoli
- Boiling 🥕 Carrots
- Frying 🥕 Carrots
- Frying 🧅 Onions
easy to add a new ingredient by creating a new chapter
easy to add a new cooking method by creating a new chapter
Multiple Dispatch is agnostic about how to order your code, which enables full flexibility without the need of rewriting already existing code.
While it may look like we lost organization alltogether, in actual programming we gain it back thanks to type-hierarchies. Broccoli and carrots would be kinds of vegetables, lenses and beans are legumes, boiling and stewing could be variations of hot-water-processing.
You can find more details about the cookbook analogy in this blog post.
Built for data science
Julia is Built for data science and applied mathematics in general.
& optimization libraries
If you are in the finance sector, or energy, chemistry, biology, medicine, engineering, quantum computing, astronomy, or many more: There are already others who have built the next best practice algorithms of your industry.